LAMBADA Dataset Papers With Code
4.6 (264) · € 23.50 · Auf Lager

The LAMBADA (LAnguage Modeling Broadened to Account for Discourse Aspects) benchmark is an open-ended cloze task which consists of about 10,000 passages from BooksCorpus where a missing target word is predicted in the last sentence of each passage. The missing word is constrained to always be the last word of the last sentence and there are no candidate words to choose from. Examples were filtered by humans to ensure they were possible to guess given the context, i.e., the sentences in the passage leading up to the last sentence. Examples were further filtered to ensure that missing words could not be guessed without the context, ensuring that models attempting the dataset would need to reason over the entire paragraph to answer questions.

GPT-3: Just Another Language Model But Bigger

sun397 TensorFlow Datasets

TeleQnA: A Benchmark Dataset to Assess Large Language Models
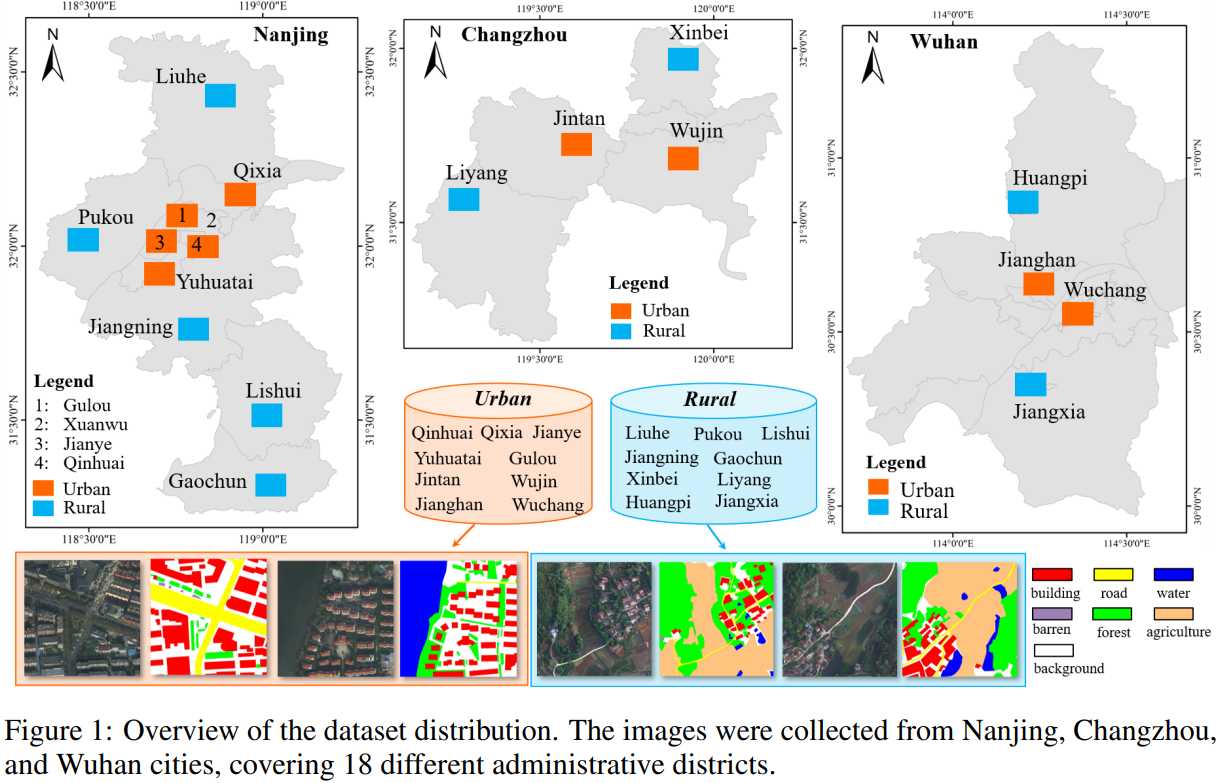
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive

PDF] Revisiting Simple Neural Probabilistic Language Models
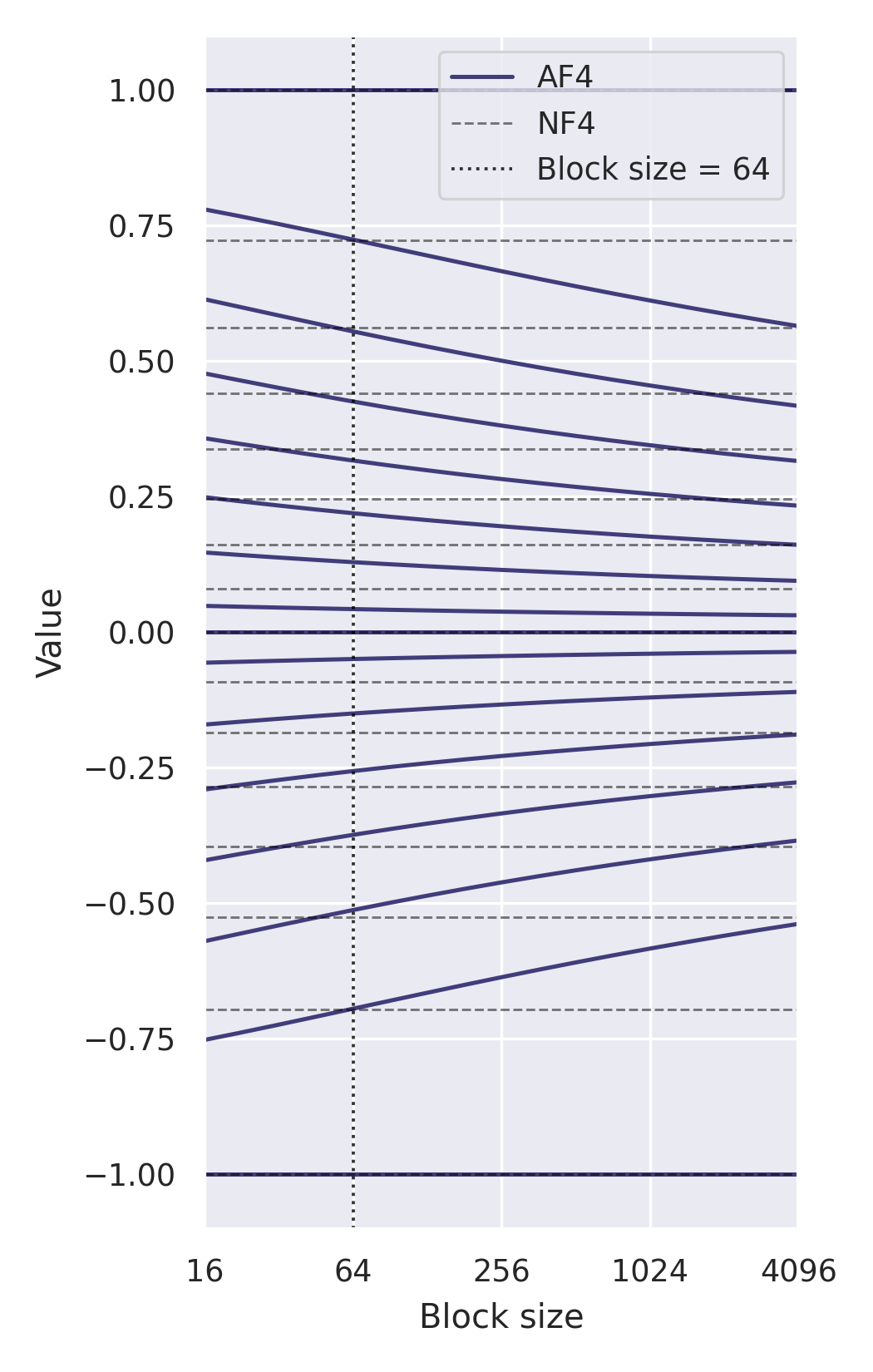
2306.06965] NF4 Isn't Information Theoretically Optimal (and

Zewei Chu - CatalyzeX
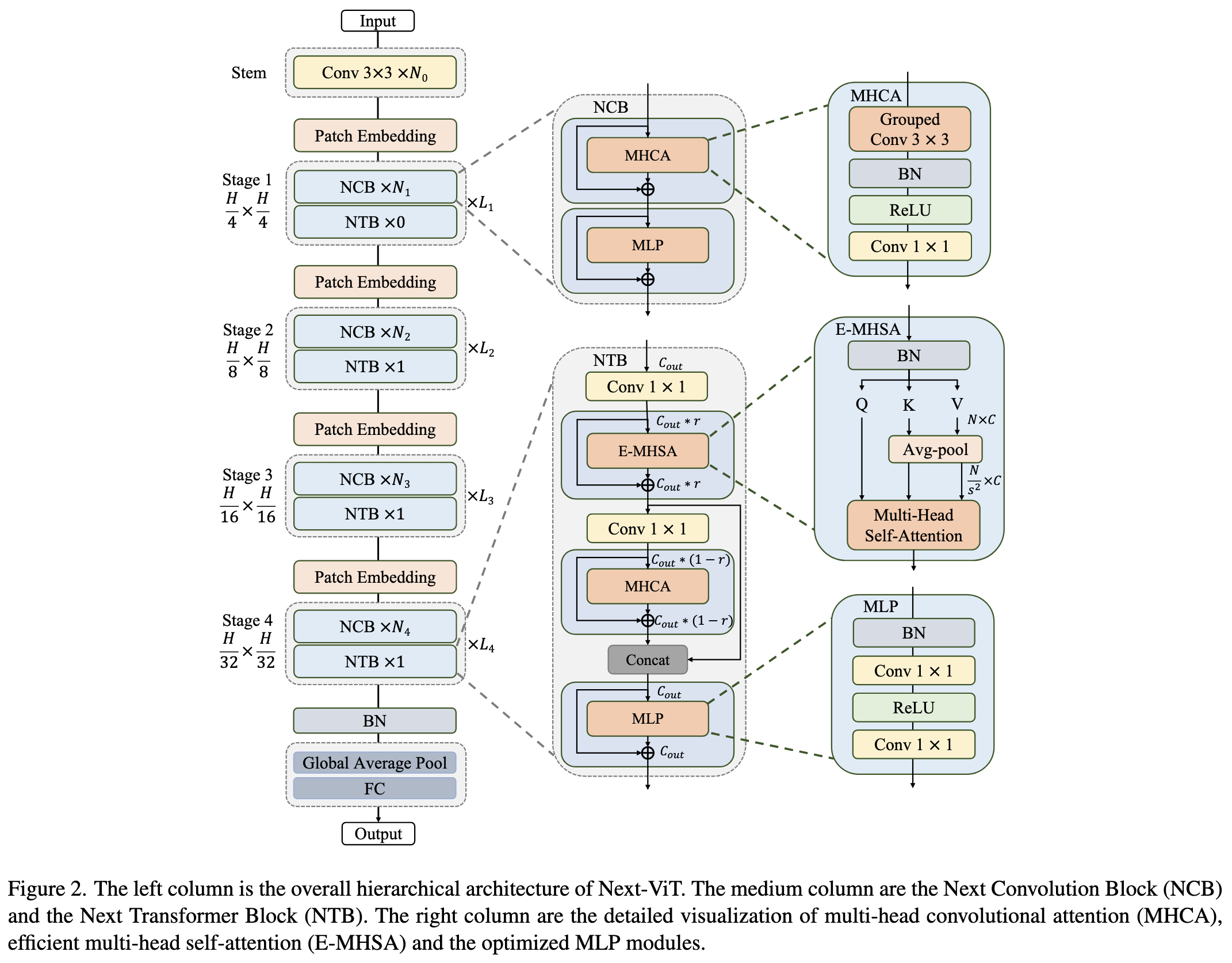
2022-7-17 arxiv roundup: Next-ViT, Anthropic & DeepMind & Google
Release raw lambada dataset · Issue #131 · openai/gpt-2 · GitHub











